1. Introduction à l’Architecture Logicielle
L’architecture logicielle est un aspect crucial du développement de logiciels, car elle définit la structure globale d’un système, détermine comment ses composants interagissent entre eux et guide les décisions de conception tout au long du processus de développement. En d’autres termes, l’architecture logicielle est la fondation sur laquelle repose tout le reste du développement logiciel.1.1 Importance de l’architecture dans le développement logiciel
Une architecture logicielle bien conçue offre de nombreux avantages :- Maintenabilité et évolutivité : Une bonne architecture facilite la maintenance du logiciel et permet d’ajouter de nouvelles fonctionnalités ou de modifier les existantes sans perturber l’ensemble du système.
- Réutilisabilité : En identifiant les composants réutilisables et en les isolant correctement, une architecture efficace favorise la réutilisation du code, ce qui accélère le développement et réduit les risques d’erreurs.
- Fiabilité et robustesse : Une architecture bien pensée permet de réduire les points de défaillance potentiels et d’assurer une meilleure gestion des erreurs, ce qui se traduit par un logiciel plus fiable et robuste.
- Performance : En anticipant les contraintes de performance dès la phase de conception, une architecture appropriée peut contribuer à garantir que le logiciel réponde aux exigences de performances attendues.
- Sécurité : Une architecture sécurisée intègre des mécanismes de protection appropriés dès le départ, ce qui réduit les vulnérabilités et renforce la sécurité globale du système.
1.2 Aperçu des modèles architecturaux courants
Aperçu des modèles architecturaux courants Il existe plusieurs modèles architecturaux couramment utilisés dans le développement logiciel, chacun avec ses propres caractéristiques et avantages :1.2.1. Architecture en couches
Ce modèle divise le système en couches distinctes, chacune responsable d’un aspect spécifique de la fonctionnalité. Les couches communiquent entre elles de manière hiérarchique, avec des règles strictes définissant les interactions.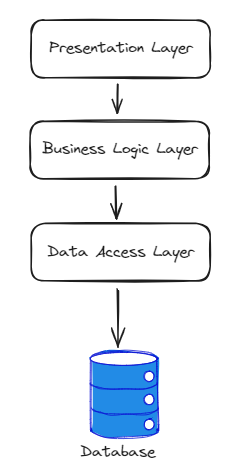 Chacune des couches de cette architecture a des responsabilités distinctes dans la conception et le fonctionnement d’une application logicielle :
a. Couche de Présentation (Presentation Layer) :
Chacune des couches de cette architecture a des responsabilités distinctes dans la conception et le fonctionnement d’une application logicielle :
a. Couche de Présentation (Presentation Layer) :
- Responsabilités :
- Interface utilisateur : Gère l’interaction entre l’utilisateur final et l’application. Cela inclut la présentation des données à l’utilisateur, la collecte des entrées utilisateur et la gestion des événements utilisateur.
- Présentation des données : Formate les données de manière appropriée pour les afficher à l’utilisateur. Cela peut impliquer la transformation des données brutes en une représentation visuelle compréhensible, comme des pages Web, des interfaces utilisateur graphiques, des rapports, etc.
- Validation des entrées utilisateur : Valide les données saisies par l’utilisateur pour s’assurer qu’elles sont correctes et cohérentes avant de les transmettre à la couche métier.
- Exemples de technologies : Pages Web, applications mobiles, interfaces utilisateur graphiques (GUI), services web, API REST, etc.
- Responsabilités :
- Traitement des données métier : Implémente la logique métier de l’application, y compris les règles métier, les workflows et les algorithmes nécessaires pour répondre aux besoins fonctionnels de l’application.
- Coordonne les interactions entre les différentes parties de l’application pour exécuter les opérations métier requises.
- Gestion des transactions : Gère la logique transactionnelle pour assurer l’intégrité des données et la cohérence des opérations effectuées sur les données.
- Exemples de technologies : Classes métier, services, composants, gestionnaires d’événements, etc.
- Responsabilités :
- Accès aux sources de données : Fournit des mécanismes pour récupérer, stocker et manipuler les données nécessaires à l’application à partir des sources de données sous-jacentes telles que les bases de données, les services web, les fichiers, etc.
- Mapping objet relationnel (ORM) : Si nécessaire, effectue le mapping entre les structures de données utilisées dans le code de l’application et le schéma de la base de données sous-jacente.
- Optimisation des requêtes : Optimise les requêtes de données pour maximiser les performances et minimiser la charge sur les sources de données.
- Exemples de technologies : Frameworks ORM (comme Hibernate pour Java, Entity Framework pour .NET), bibliothèques de base de données (comme JDBC pour Java, ADO.NET pour .NET), requêtes SQL, API REST, etc.
1.2.2. Architecture Hexagonale (Ports and Adapters)
L’architecture hexagonale, également connue sous le nom de Ports and Adapters, est centrée sur le principe de séparation des préoccupations. Elle propose de diviser un système en trois couches principales :- Le domaine métier (ou noyau) : C’est le cœur de l’application où réside la logique métier. Il est indépendant de toute technologie externe et ne connaît pas les détails de mise en œuvre des autres couches.
- Les adaptateurs (ou ports) : Ils servent d’interface entre le domaine métier et les composants externes tels que les bases de données, les API externes, les interfaces utilisateur, etc. Les adaptateurs convertissent les données et les actions du domaine métier en formats compréhensibles pour les composants externes.
- Les adaptateurs externes : Ils implémentent les adaptateurs en fournissant des détails concrets de mise en œuvre pour les composants externes. Par exemple, un adaptateur de base de données serait responsable de la persistance des données dans une base de données spécifique.
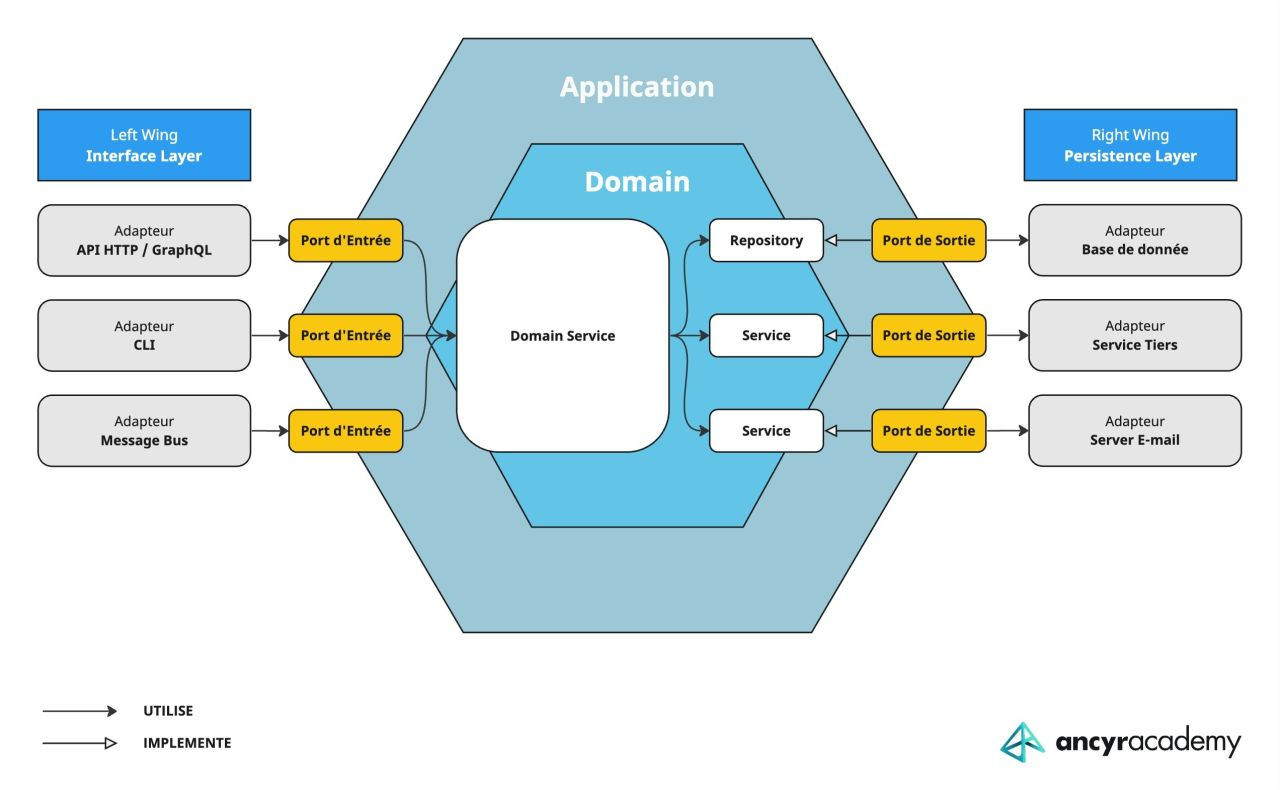
1.2.3. Clean Architecture
La Clean Architecture, met l’accent sur la séparation des préoccupations et la maintenabilité du code. Elle organise un système en plusieurs cercles concentriques, avec chaque cercle représentant un niveau d’abstraction différent :- Cercle interne (Domaine) : Il contient les entités métier, les règles métier et la logique métier de l’application. Ce cercle est le plus fondamental et ne dépend d’aucun autre élément de l’application.
- Cercle intermédiaire (Cas d’utilisation) : Il contient les cas d’utilisation spécifiques à l’application, qui orchestrent les interactions entre les entités métier pour réaliser des fonctionnalités spécifiques.
- Cercle externe (Interfaces utilisateurs et Frameworks) : Il contient les détails d’implémentation spécifiques à l’infrastructure, tels que les interfaces utilisateur, les bases de données, les frameworks, etc. Ce cercle est le plus externe et le moins stable.
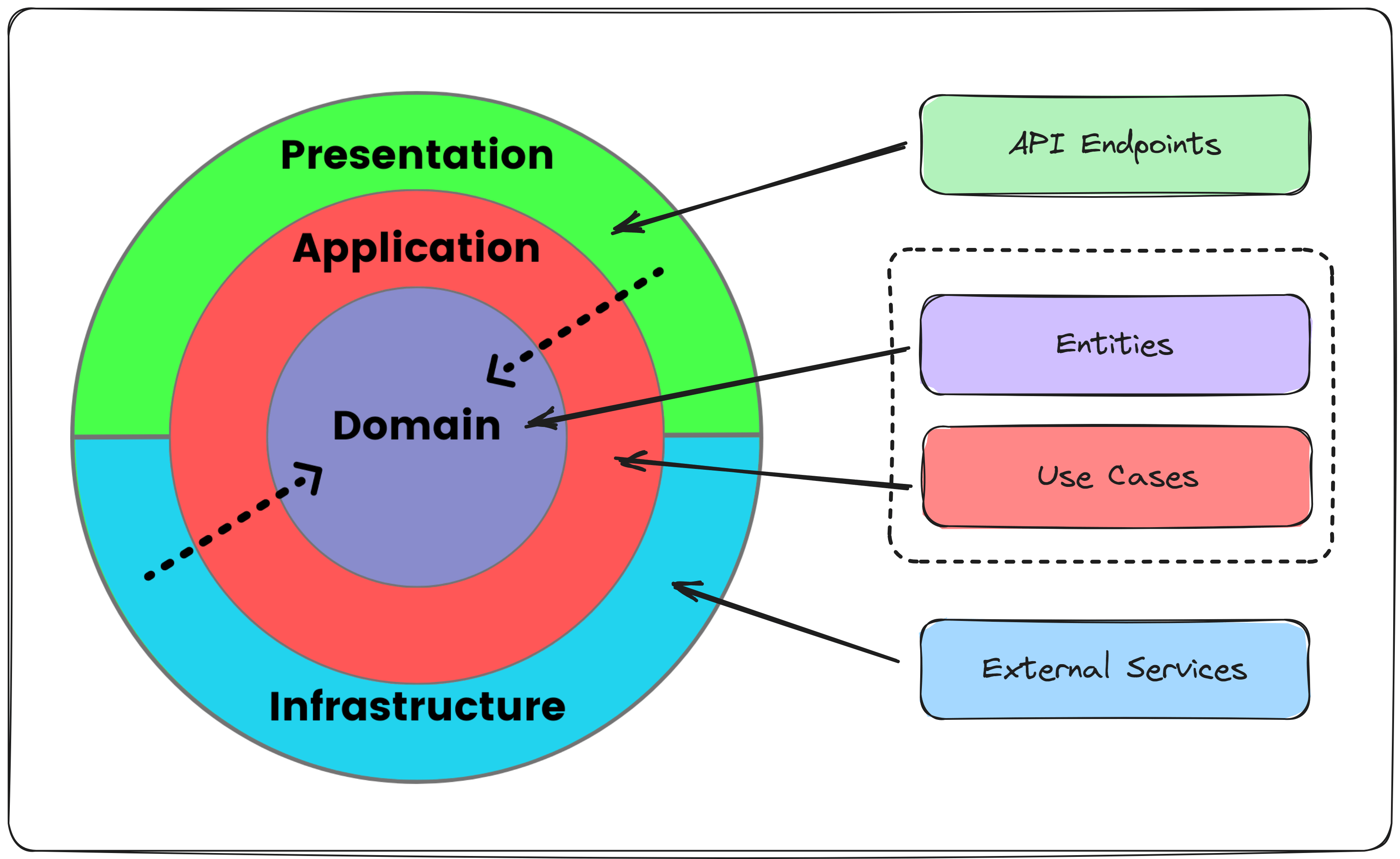
1.3 Différence entre l’architecture en couches, Hexagonal et la Clean Architecture
Les architectures en couches, Hexagonal et Clean Architecture sont toutes des approches de conception logicielle visant à créer des systèmes modulaires, maintenables et évolutifs. Chacune de ces approches présente des caractéristiques distinctes et peut être adaptée en fonction des besoins spécifiques d’un projet. Voici les principales différences entre ces trois types d’architectures :- Architecture en Couches :
- Principe fondamental : L’architecture en couches organise le système en différentes couches logiques, avec chaque couche responsable d’un aspect spécifique de l’application.
- Structure : Typiquement, une architecture en couches comporte des couches telles que la présentation (interface utilisateur), la logique métier et l’accès aux données. Les couches communiquent entre elles de manière hiérarchique, avec des règles strictes définissant les interactions.
- Avantages : La séparation des préoccupations permet de maintenir le code plus propre et plus modulaire. Cela facilite également la réutilisation des composants et permet une meilleure scalabilité.
- Inconvénients : Les dépendances hiérarchiques peuvent rendre le système plus rigide et moins flexible. De plus, la communication entre les différentes couches peut introduire des surcoûts de performance.
- Architecture Hexagonale (ou Ports and Adapters) :
- Principe fondamental : L’architecture hexagonale met l’accent sur la séparation des préoccupations en isolant le cœur fonctionnel de l’application (le “hexagone” ou “noyau”) de toute dépendance externe.
- Structure : Le cœur de l’application (domaine métier) est entouré de ports, qui représentent des points d’entrée et de sortie génériques pour les interactions avec le système. Les adaptateurs sont des composants qui convertissent les données provenant des ports en un format compréhensible par le domaine métier, et vice versa.
- Avantages : Cette approche favorise la flexibilité en permettant de remplacer facilement les composants externes sans affecter le domaine métier. Elle rend également les tests unitaires plus simples, car la logique métier est isolée et peut être testée indépendamment des dépendances externes.
- Inconvénients : L’architecture hexagonale peut nécessiter un niveau supplémentaire d’abstraction et de complexité, ce qui peut rendre la conception initiale plus difficile.
- Clean Architecture :
- Principe fondamental : La Clean Architecture met l’accent sur la séparation des préoccupations et la maintenabilité du code en organisant le système en plusieurs cercles concentriques, avec chaque cercle représentant un niveau d’abstraction différent.
- Structure : La Clean Architecture divise un système en cercles concentriques, avec le cercle interne contenant le domaine métier fondamental, le cercle intermédiaire contenant la logique d’application spécifique à l’application, et le cercle externe contenant les détails d’infrastructure et d’interface utilisateur.
- Avantages : La Clean Architecture vise à rendre le système évolutif, maintenable et testable en minimisant les dépendances entre les différentes couches et en favorisant le principe d’inversion de dépendance.
- Inconvénients : La Clean Architecture peut nécessiter une planification et une conception plus approfondies pour définir clairement les limites entre les différents cercles et assurer une séparation efficace des préoccupations.